
Example of Annotated Preface Page
“Behind Aiiieeeee!” gives readers, especially students, the resources and contextual information they need to fully appreciate Aiiieeeee! (and, eventually, The Big Aiiieeeee!) and the field of Asian American cultural production more broadly.
This will be done through a combination of traditional and non-traditional media platforms. For example, the plan is to get Aiiieeeee! back in print, but also have it published as an e-book (Update October 2019: Success! A new edition has been published with University of Washington press!). In the long term, I plan to write a scholarly monograph and edit a series of critical essays on the topic (perhaps using, in the nearer future, a special journal issue as a jumping off point). But the heart of the project is the digital humanities component, in the form of a digital edition.
What is a digital edition?
It seems to mean many things to many people. If you’re interested, you can read a collection of probing essays on the subject and its theory and history here. In the most basic sense, you could think of a digital edition as just a digital version of any kind of Norton Critical Edition: essentially, a book republished with a whole bunch of footnotes, annotations, scholarly commentary — the critical apparatus — and, particularly with older texts where multiple versions proliferate, comparisons of those different versions. Some examples of this are below, which are screenshots drawn from digital editions of works by Woolf and Thoreau. (Both of these sites also showcase something new and cool that digital editions allow, which is the inclusion of high-quality scans and transcriptions of original manuscript pages). Click the screenshots to visit the sites.


Sites like these are, obviously, immensely valuable resources for Woolf and Thoreau scholars. But to your average lay reader — or even your average English major — the presentation format is overwhelming, intimidating, and seemingly irrelevant: so there were multiple versions, you can imagine the casual visitor to this site thinking, but who cares? This, of course, isn’t new or unique to digital editions — it seems to me part of why critical editions have always had a relatively specific and limited audience.
Beyond digital editions are another subset broadly called digital exhibits or digital archives. Essentially these are what the name implies: a repository of digitized artifacts that have been collected onto a website, and which users can browse through by clicking various links and tags. Below are a few different examples of these, all of which are worth taking a little time to explore
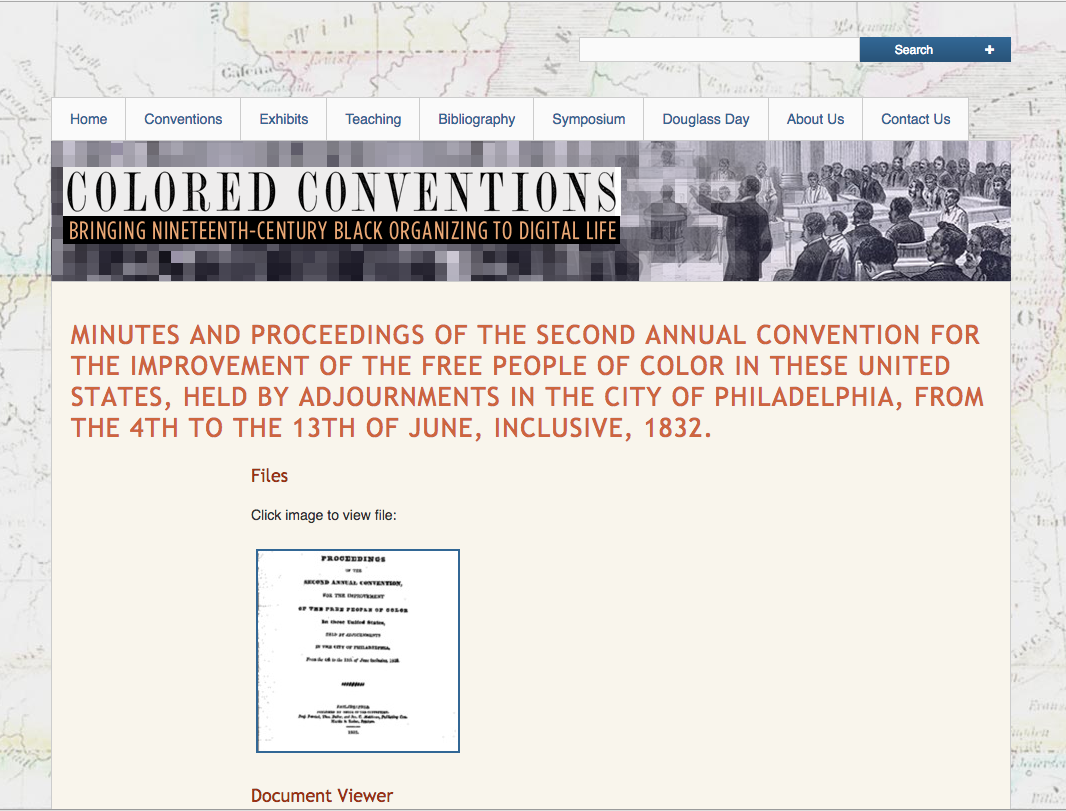
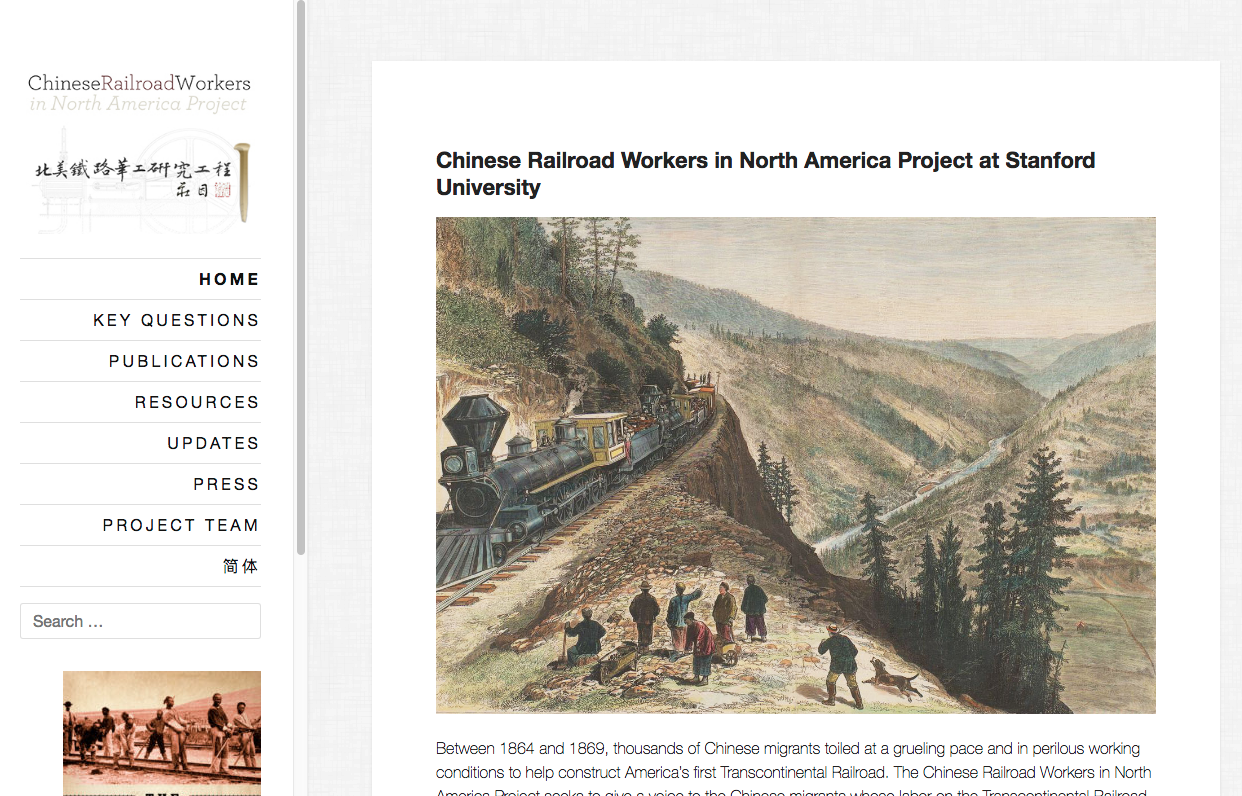
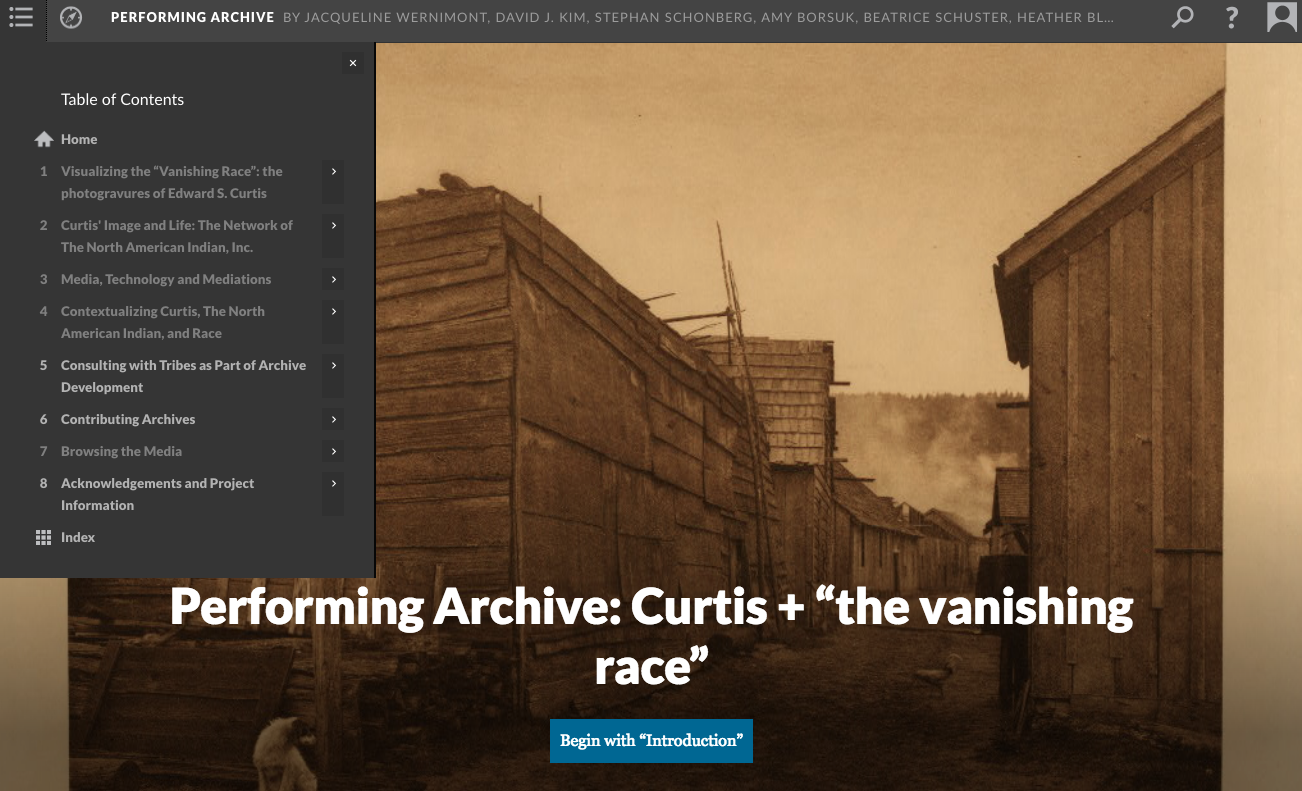
Like the digital editions discussed earlier, the difficulty which these digital exhibits present is that they tend to make the user feel at sea, forced to make broader sense of all the annotations and information on their own, not quite clear where to start or go next.
The challenge for this project, then, is to try to combine the advantages of these sites — the wealth of information and scholarly expertise — but bring them to bear on Aiiieeeee! in a way that doesn’t overwhelm or discourage the user.
What’s your plan?
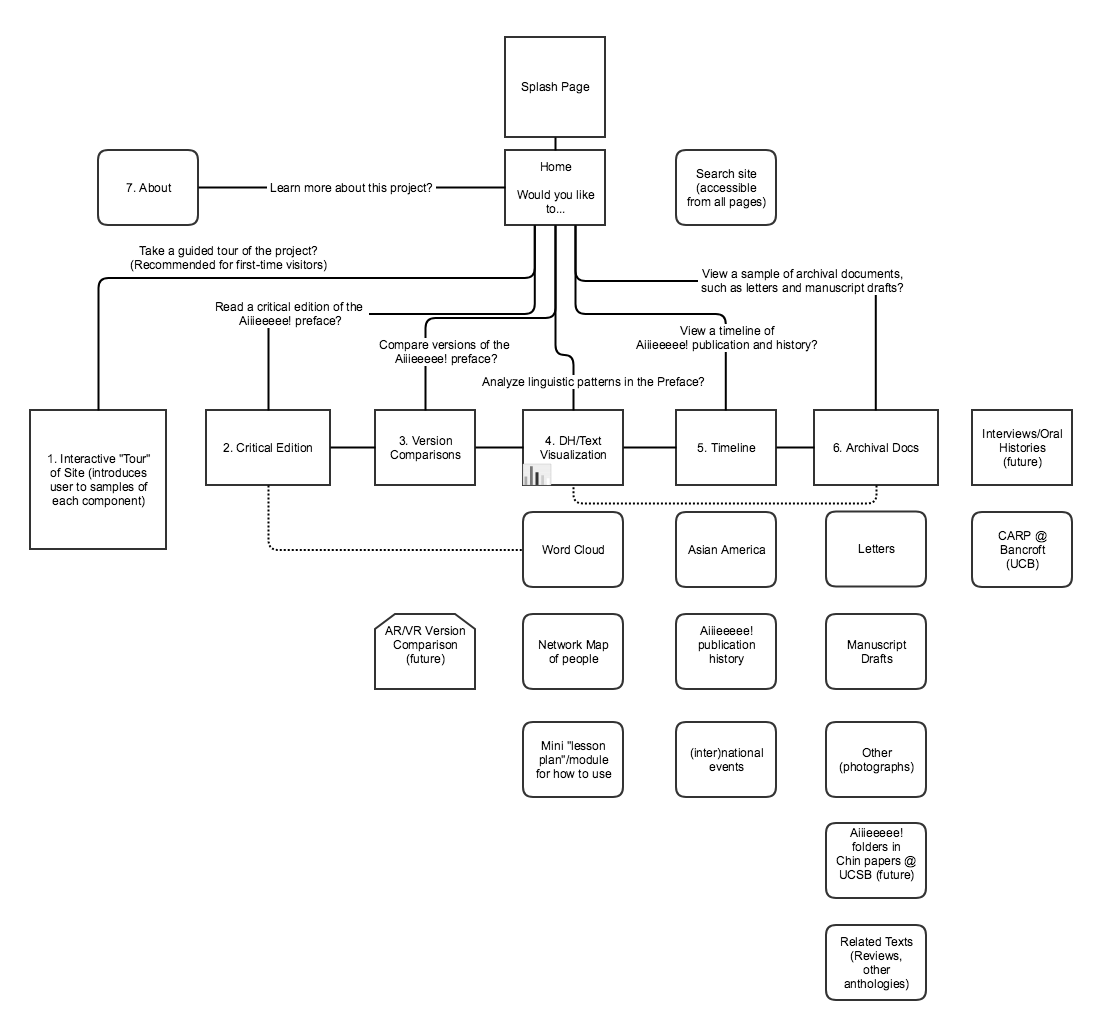
Below is a rough, and probably incomprehensible, sketch of the Site Map for the digital edition/website I’m envisioning. Take it for what you will; I’m placing it here mostly for posterity, as the final project will probably look little like this initial vision. And don’t worry, no one looking at the site will ever see anything like this; it’s just the back-end.
In all of the examples I’ve given of digital works, the limitations are less those of their creators’ than the constraints of the platforms and digital tools being used. So, one of the difficulties we face is locating — or, more likely, inventing — appropriate tools. We would ultimately need a programmer with experience as well as vision, and funding to support such a person. So in the long run, I am looking to build a team. But for now, we’re constrained by the tools we choose, and for us, that will mean using a web-publishing platform called Omeka Classic (click “Showcase” to see some examples of sites built with it.) This is where I’ll start putting together the initial prototypes, which we can then build on and use to justify the need for development grants, etc.
Omeka is still very powerful, and has a suite of interesting plug-ins — particularly one called Neatline — that are worth experimenting with, however. Below are some mockups of the sort of visual storytelling we could do for Aiiieeeee! in the form of an Annotated Preface and a sample archival document; a text visualization (i.e. a visual representation of various linguistic patterns in a given corpus of text, in this case the Preface and Intros — I haven’t built this yet, but you can read a simplified overview of the general process on this UT Austin blog post); and a Timeline. These are all ways of providing valuable context to the user; the question, however, is the best way to guide them to and through it. (That’s part of why having a larger team, and tech people, to think through and hash this out would be ideal.)


Where does the Aiiieeeee! archive fit in?
Upon hearing about Shawn Wong’s archive, my first inclination was simply: digitize it. Digitize It All… and then put it online so everyone can enjoy it!
But it wasn’t long before my naïveté became apparent.
First, there was the question of manpower. It’s not a huge deal to feed 10,000 pieces of paper through a scanner, and to find an external hard drive and ultimately a server to put all these PDFs or image files onto. It could be done by a single person in a span of weeks or months. Far more time consuming, however, is the identification and classification process, especially the OCR cleanup (i.e. ensuring the text transcription has no errors) and metadata tagging. For it to be useful in an archive, digital or otherwise, every individual piece of paper would have be identified and relevant information extracted: who wrote this letter? to whom? What date? What is it discussing, in general terms? What folder was it found in?
On top of that, there were permissions and privacy issues. Hundreds of individuals would have to give their permission before I could make digital copies of their letters available publicly online. If publishing portions of the book online with a critical apparatus, copyright issues would have to be dealt with.
In the end, though, the biggest deterrent was not logistical. I would have been more than happy to spend the time identifying, scanning, and obtaining permissions for every single piece of paper in the four boxes I am even now looking at while I type this. The reason I’ve decided *not* to do this at the moment is because, having consulted now with several different archivists, librarian, and digital humanities experts, it’s clear that it’s not the best way to achieve the current goal — which is, first, to bring the reader in, to tell them a story and tantalize rather than inundate them with documents.
To be clear, my ultimately goal is indeed to digitize everything, and to make it as accessible as I can. To that end, I’m hoping we can eventually get a digitization grant and also bring students in to make it a valuable classroom experience. But for the moment, I’ve instead begun to go through the archive selectively, creating a finding aid (see screenshot below) and digitizing the most relevant documents that would help a reader understand really important things — like how difficult it was to get Aiiieeeee! published, and how and why it was that Howard ultimately did; how each of the four editors envisioned the project and their role in it; their communications with Asian American writers like Wakako Yamauchi and Hisaye Yamamoto; that sort of thing. It’s from this kernel that I envision the digitization project coming to fruition in the long run. (I badly want to put a few of those documents up on this page so you can see them, but this is precisely where the open-access copyright issues come up.)

One last note about the archive: it is manifold. Beyond what I have in my possession, there are two particularly important pieces I would love to eventually incorporate into the digital edition/site:
- the CARP Oral histories/interviews the editors originally did with numerous Asian American writers, artists, and prominent figures around 1973 (apparently housed at the Bancroft at UC Berkeley, though I’ve had difficulty locating it through the library’s online search); and
- The Aiiieeeee! folders mentioned in the finding aid to Frank Chin’s papers at the UCSB Special Collections.
Who is going to use this, again?
Scholars and researchers of Asian American cultural production, who already “know” Aiiieeeee!, will find the archival material and scholarly monograph useful for shedding light on publication and reception history. They will especially appreciate the digital components as an interactive learning module they can assign their undergraduate or graduate students as a springboard for discussion and further inquiry. (Both audiences will value an e-book version of Aiiieeeee! for its ease of use, searchability and, particularly for the digitally-inclined, the potential of a standardized digital corpus for textual analysis). Students of ethnic literature and post-1945 America, in particular, will appreciate the developmental narrative and historical context provided for the Preface, while also being introduced to the excitement of discovering archival “clues” and original documents. The site can also serve as a case study and model for others working in the digital humanities interested in creating effective digital editions and companion sites of their own.
So, what’s next?
The first step is to talk to a press and establish the potential for both a hard copy and an e-book reprint — and to gauge press interest in and resources for constructing some part of the digital companion site. In the meantime, I’ll also be setting up an Omeka server and domain name to establish an online “homebase” (!) for the various prototypes and images I collect and create. Over the next year or so, my goal is to create working models of the Preface critical apparatus, the timeline, and some text visualizations, while at the same starting to pursue scholarly output opportunities in the form of the special journal issue and potential presentations at conferences, symposiums, or working groups.
